目录
pyinstaller打包的基于paddleOCR的可执行文件启动报错
很多人的图片转文字功能都采用 paddleOCR项目,为了发布给用户使用,往往要借助pyinstaller等打包工具。使用pyinstaller打包paddleOCR为可执行后,很多开发者遇到,可执行文件启动报错:未找到模块。
网友kerneltravel 综合分析了多个issue和pyinstaller的报错信息后,找到这个问题的原因,并给出了解决方法,同时向paddleOCR官方提交了修复代码(见 PR1 和 PR2 ),以PR2 为准。
下面对这个问题做具体分析:
问题表现:
-
打包后,paddleocr应用启动报错信息1:
Traceback (most recent call last): File "main.py", line 5, in File "PyInstaller\loader\pyimod02_importers.py", line 385, in exec_module File "paddleocr_init_.py", line 14, in File "PyInstaller\loader\pyimod02_importers.py", line 385, in exec_module File "paddleocr\paddleocr.py", line 33, in File "importlib_init_.py", line 126, in import_module ModuleNotFoundError: No module named 'tools' [11752] Failed to execute script 'main' due to unhandled exception! -
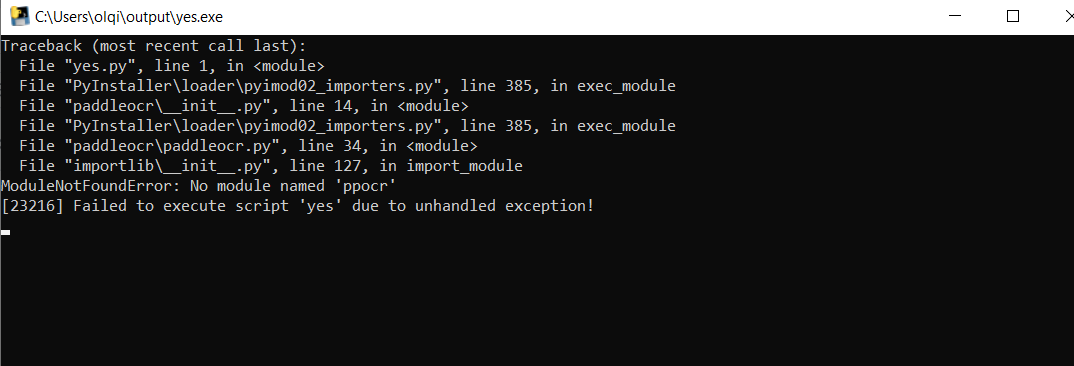
启动报错信息2:
raceback (most recent call last): File "yes .py",line 1, inFile"PyInstaller\loader pyimod02 importers.py", line 385,in exec moduleFileFile"paddleocrinit .py",line