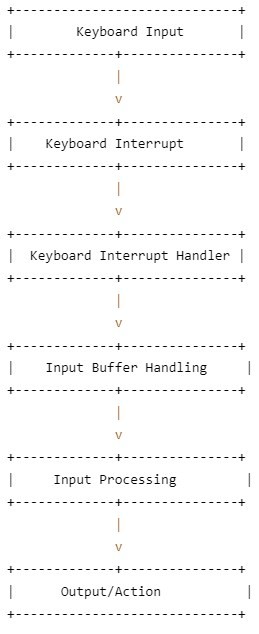
帮助初学者理解和运行大模型的本地离线训练、运行流程:
大模型在本地离线运行的流程通常包括以下几个步骤:
-
下载训练代码:首先,你需要下载相关的训练代码。通常,大模型的训练代码会在开源的代码库中进行维护,你可以通过GitHub等平台搜索到相应的代码。
-
准备环境:在运行代码之前,你需要确保你有相应的环境来支持模型的运行。这包括正确配置Python环境、安装相应的依赖库以及GPU驱动等。
-
下载模型数据文件:大模型通常需要预训练的权重文件作为输入。你可以通过官方的提供的链接或者其他渠道下载这些模型数据文件,并保存到本地。
-
修改配置:有些大模型的代码会提供一个配置文件,你需要根据自己的需求对配置文件进行修改。配置文件中包括了输入输出文件路径、超参数等设置,你可以根据实际情况进行修改。
-
运行代码:根据具体的代码说明,你需要运行相应的命令来启动模型的训练或推理过程。在运行之前,确保你已经正确设置好模型数据文件的路径和其他配置项。
综上所述,要在本地离线训练大模型,你需要下载训练代码、准备环境、下载模型数据文件、修改配置、运行代码。这个流程可能因模型的不同而有所差异,但基本思路是相通的。
如何使用训练好的模型得到输出?
下面是使用已训练好的模型进行推理的一般步骤:
-
加载模型:使用相应的深度学习框架(如TensorFlow、PyTorch等),加载已训练好的模型权重文件。通常可以通过指定模型的名称或文件路径来加载模型。
-
数据预处理:将输入数据进行预处理,使其与训练数据具有相同的格式和表示。这可能包括词向量化、标准化、缩放或其他必要的数据处理步骤。
-
推理过程:根据模型的类型和任务,使用加载的模型对输入数据进行推理。这涉及将输入数据传递给模型,并获取模型的输出结果。
-
后处理:根据任务的需求,对模型的输出进行后处理。例如,对于分类任务,可以应用一个阈值来确定最终的类别标签。
-
获取输出结果:根据需要,将模型的输出结果格式化为可读的文本、图像、数值等形式,并返回给用户或保存到文件中。
需要注意的是,每个具体模型和任务的实现方式可能有所不同,所以以上步骤需要根据具体的模型和任务进行调整。你可以查阅相关模型的文档或参考例子来了解更详细的使用方法。… 查看余下内容

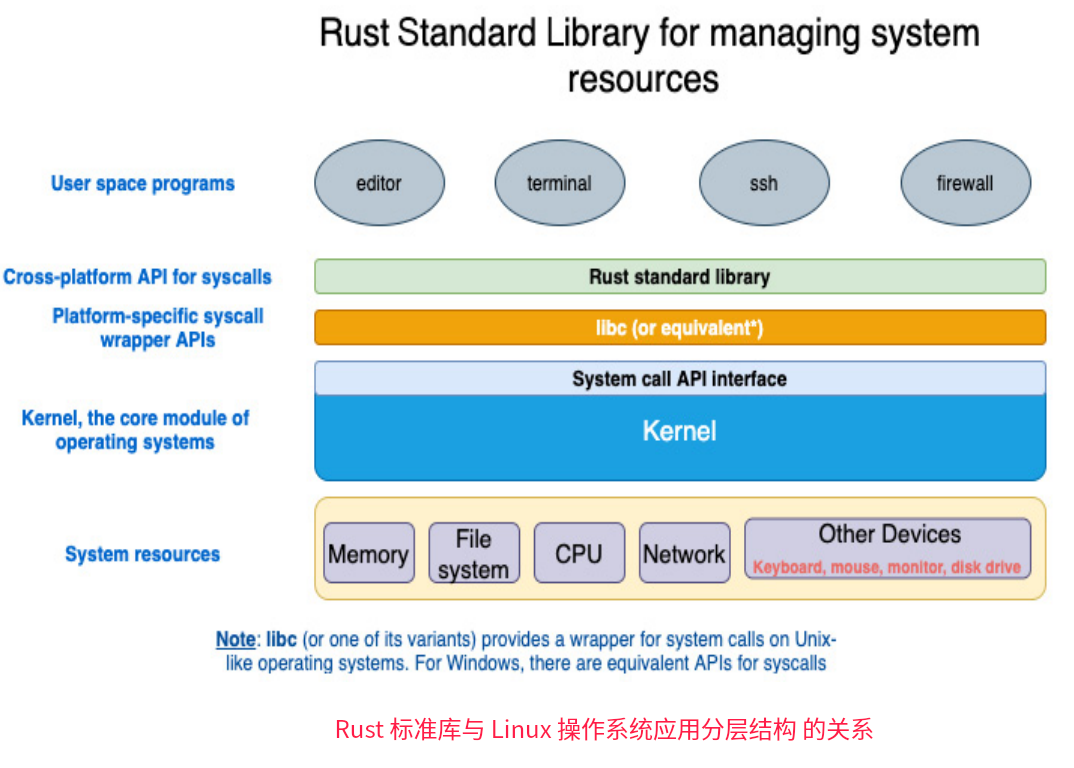
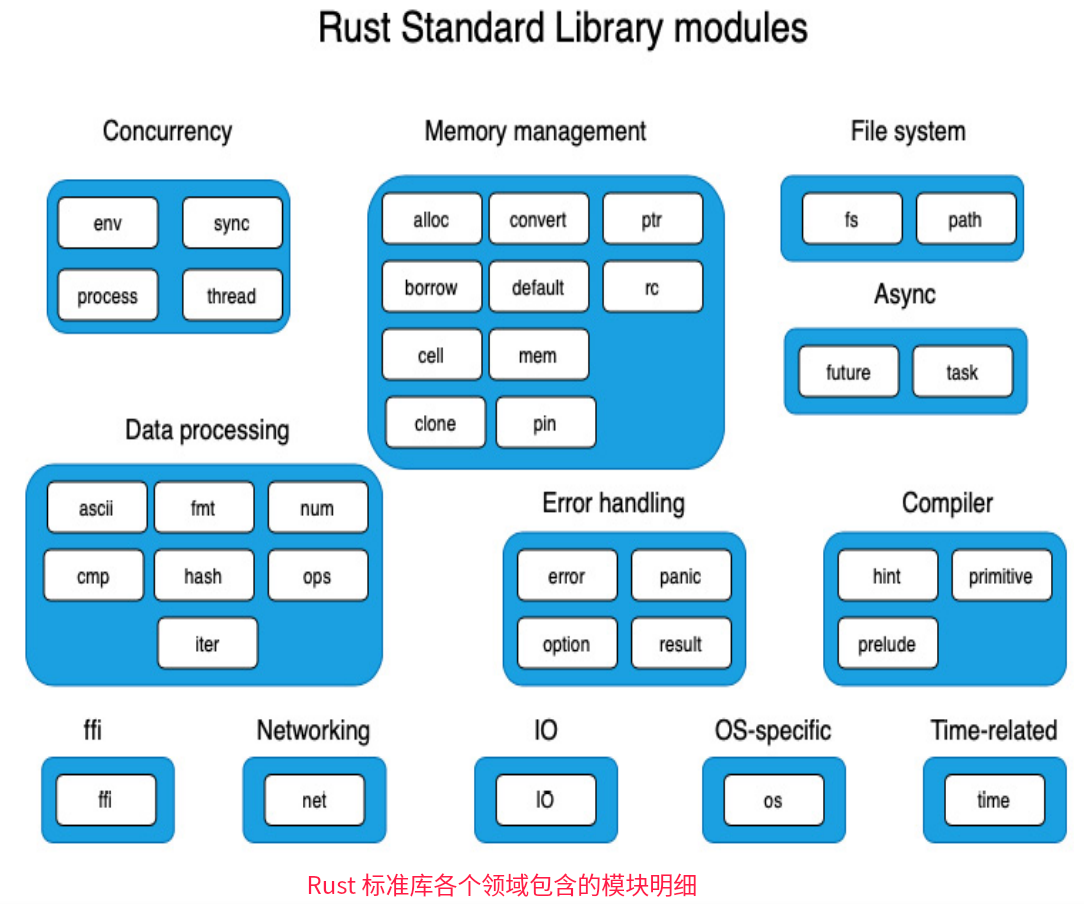
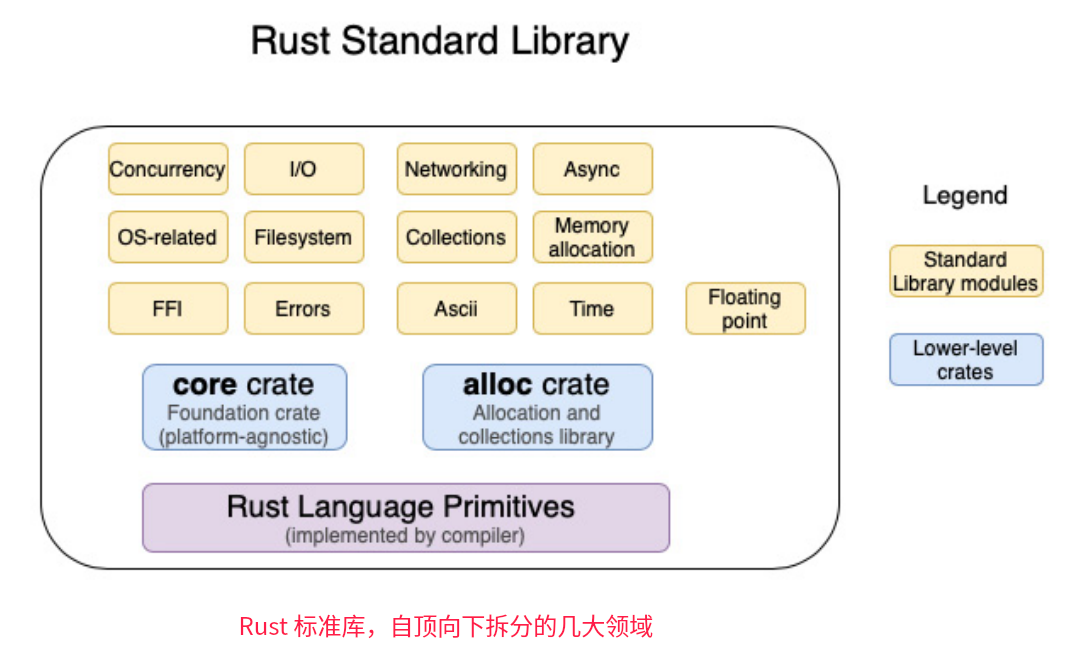 libc(或其变体)为类UNIX操作系统上的系统调用提供了一个包装器,如Linux内核实现了POSIX标准指定的数百个POSIX API(对于Windows,系统调用有等效的API,也实现了
libc(或其变体)为类UNIX操作系统上的系统调用提供了一个包装器,如Linux内核实现了POSIX标准指定的数百个POSIX API(对于Windows,系统调用有等效的API,也实现了