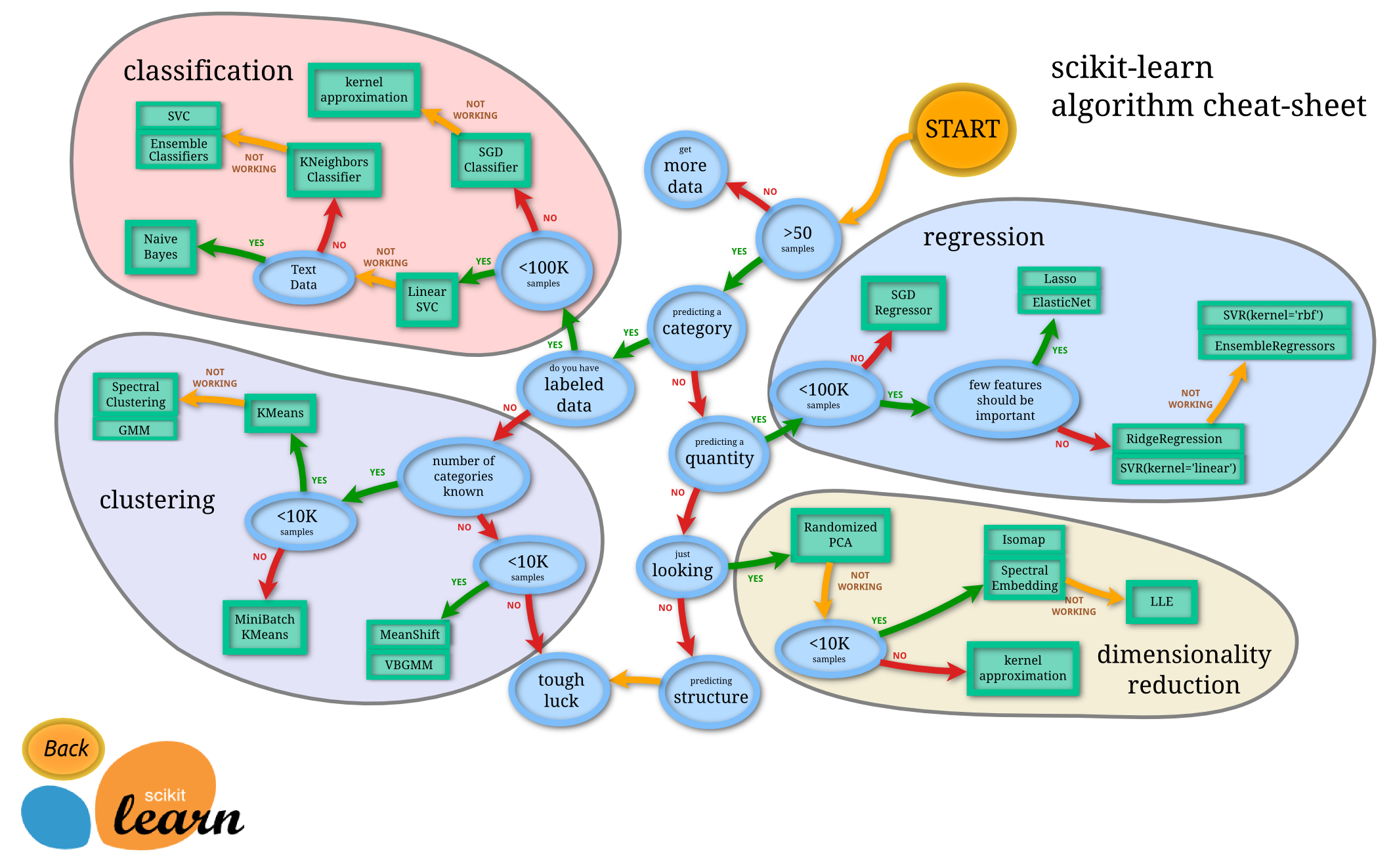
Scikit-learn algorithm cheat-sheet 是一个流程图(算法速查表),旨在帮助用户选择适合其数据集的机器学习算法。该图根据数据集的属性(例如数据类型、数据量、标签类型等)和任务类型(例如分类、回归、聚类等)提供了一系列适合的算法建议。
假设我们有一批样本(样本数量少于50个),则根据算法速查表,会进入“get more data”流程,也就是样本数量不足,不建议基于这批样本进行机器学习。
再假设我们有一批样本(样本数量11万,样本CSV数据中有一列作为某个方面的数据的LABEL,即带有结果的数据),我们希望基于样本学习后,对以后新的数据进行类别预测。 那么根据流程,predicting a category(是预测类别的问题吗) ->YES(是)-> do you have labeled data(样本是否有标签)-> YES(是)。 流程至此,就到了图中的 “Linear SVC”算法位置
使用该工具选择模型算法的步骤如下:
-
确定数据集的属性和任务类型。
-
根据数据集的属性和任务类型在流程图中找到相应的部分。
-
根据流程图中的建议选择适合的算法。
-
根据所选算法的文档和示例学习如何使用该算法。
需要注意的是,该流程图只是一个参考工具,不是绝对的规则。选择模型算法时需要综合考虑数据集的实际情况以及算法的优劣势,并进行实际测试和评估。
此外,Scikit-learn algorithm cheat-sheet 的原理是基于机器学习算法的特性、优劣势以及适用场景等因素,将常见的机器学习算法分成了几个大类,并在流程图中以可视化的方式展示了它们之间的关系和特点。这为选择合适的机器学习算法提供了一个初步的参考,帮助用户在众多的机器学习算法中快速找到适合自己数据集的算法。
