Rust开发的项目达到一定的规模时,要如何组织代码,特别是package、crate和module?这些概念在项目规模增大的时候尤其重要,甚至影响项目后续的生命力。
本文是来自 参考链接[1]的Rust专家的建议的《上篇》,可以帮助避免常见的陷阱、性能问题或编译问题。
中文文章内容如下:
IC (一个开源的区块链项目)的 Rust 代码库从 2019 年 6 月的空存储库增长到 2022 年初的近 350000 行代码。这种快速增长告诉我,对于相对较小的项目来说,运作良好的决策可能会随着时间的推移开始拖累项目。本文评估了 Rust 代码组织选项,并提出了有效使用它们的方法。
Rust的重要“角色”
Rust 的一些术语容易令人困惑,例如术语crate(中文“单元包”,在下文将保留为crate,不再翻译为 单元包)就不太直观。即使是令人尊敬的 《The Rust Programming Language》一书的第一版也包含以下误导性段落:
Rust 有两个与模块系统相关的不同术语:“crate”和“module”。crate在其他语言中是“库”或“包”的同义词。因此,“Cargo”作为 Rust 包裹管理工具的名称:您将crate 与 Cargo 一起分享给其他人。Crate 可以生成可执行文件或库(.so 文件 或 .dll 等都属于动态库),具体取决于项目。
然而,库和包是不同的概念,不是吗?混淆这些概念会导致挫败感,即使你已经有几个月的 Rust 经验。工具约定也会导致混乱:如果 Rust 包定义了库 crate, cargo 则会自动从包名派生库名称。您可以覆盖此行为,但请不要这样做。
接下来让我们熟悉经常打交道的几个概念。
Rust 的 Module (模块)
Module 模块 是代码组织的单元。它是函数、类型和嵌套模块的容器。模块还指定它们定义或重新导出的名称的可见性。
Rust 的 Crate (单元包)
Crate 是编译和链接的单位。Crates是语言的一部分( crate 是一个关键字),但你在源代码中没有太多提及它们。库和可执行文件是最常见的 crate 类型。
Rust 的 Package (包)
包是软件分发的单位。包不是语言的一部分,而是 Rust 包管理器 Cargo 的工件 。一个 Package 可以包含一个或多个 crate:最多一个库和任意数量的可执行文件。
再论 Modules 与 Crates
当您将大型代码库分解为组件时,有两种极端情况:拥有几个包含大量模块的大包(但包数量不多)或具有大量小包(包拆分后数量较多)。
对于前一种情况,即拥有少量包含大量模块的软件包,具有一些优点:
-
添加或删除模块比添加或删除包工作量更少。
-
模块更加灵活。例如,同一 crate 中的模块可以形成依赖循环:模块可以使用来自模块的定义,而模块又可以使用来自其他模块如 foo bar foo 的定义。相反,包依赖项关系图必须是非循环的。
-
您不必每次重新排列模块时都修改 Cargo.toml 文件。
在 Rust 即时编译的理想世界中,将存储库转换为包含许多模块的庞大包将是最方便的设置。目前痛苦的现实是,Rust 需要相当长的时间来编译,而模块并不能帮助你缩短编译时间:
编译的基本单元是一个crate,而不是一个模块。您必须重新编译 crate 中的所有模块,即使您只更改一个模块。放入crate的代码越多,编译所需的时间就越长。
编译项目时,cargo对不同的crate可以并行编译,而不是在逐个crate编译。所以如果你有几个大包,你就不能充分利用多核CPU的潜力。
这两种拆分方式,是便利性和编译速度之间的权衡。Modules模块很方便,但不能帮助编译器减少工作量。Package包不太方便,但随着代码库的增长,编译速度会更好。
项目代码结构的建议
拆分依赖项中心。
有两种类型的依赖项中心:
-
具有大量依赖项的包。例如IC代码库中的两个示例(examples)是包含集成测试辅助代码(proptest策略,模拟和伪造组件实现,帮助程序函数等)的 test-utils replica 包,以及实例化所有组件的包。
-
具有大量反向依赖项的包。例如IC代码库中的示例,包含通用类型定义的 types 封装,以及指定元件接口的 interfaces 封装。
IC项目的包依赖关系图的一部分。图中 types 和 interfaces 是二类依赖中心,relica是一类依赖中心,test-utils 既是一类,又是二类依赖中心。
依赖中心是及其关键的,因为它们会对增量编译速度产生重大影响。如果您修改具有许多反向依赖项的软件包(例如图中的 types ),cargo 必须重新编译所有这些依赖项以检查您的更改。
有时可以消除依赖关系中心。例如,包 test-utils 是一些独立实用程序的联合。我们可以按它们所属的测试组件对这些实用程序进行分组,并将对应的实用程序代码分解到多个
但是,更常见的是,依赖中心将不得不保留。某些 types 类型是普遍存在的。包含这些类型的包注定是二类依赖项中心。连接所有组件的 replica 包注定是一类依赖中心。您能做的最好的事情就是本地化连结并使它们小而稳定。
请考虑使用泛型和关联类型来消除依赖项。
这个建议需要一个例子,所以请耐心等待。
types 、 interfaces 和 replicated_state 是 IC 代码库中的首批封装之一。该 types 包,含有通用类型定义,interfaces包定义软件组件的特征,replicated_state 包定义 IC 的复制状态机数据结构, ReplicatedState 类型位于根目录。
但是为什么我们需要这个 types 包呢?既然Types是接口的一个组成部分,那为什么不在interfaces 包内部定义Types呢?
原因是某些接口引用了该 ReplicatedState 类型。 replicated_state 包依赖于types包中的类型定义。如果所有类型都存在于 interfaces 包中,可能导致 replicated_state 和 interfaces 之间存在循环依赖关系。
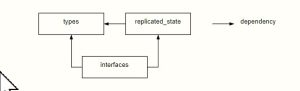
如图,types、 interfaces 和 replicated_state 包的依赖关系图。
当我们需要打破循环依赖时,我们可以将公共定义移动到新包中或合并一些包。 replicated_state 包很重;我们不想将其内容合并入interfaces包。因此,我们采用了第一个选项:将不同interface 和replicated_state 包之间共享的类型移动到 types 包中。
interfaces 包的特征定义有个特点:特征仅取决于 ReplicatedState 类型名称。这些特征不需要知道 ReplicatedState 的定义。
trait StateManager {
fn get_latest_state(&self) -ReplicatedState;
fn commit_state(&self, state: ReplicatedState, version: Version);
}这段代码是interfaces包的特征定义的示例,它依赖于ReplicatedState类型。
interfaces 包中有个例子演示了依赖于 ReplicatedState 类型的特征定义。
此属性允许我们打破interfaces 与 replicated_state 之间的 直接依赖关系。我们只需要用泛型类型参数替换确切的类型。
trait StateManager {
type State; //< We turned a specific type into an associated type.
fn get_latest_state(&self) -> State;
fn commit_state(&self, state: State, version: Version);
}不依赖于 ReplicatedState 的 StateManager的特征定义的通用版本。
基于此,我们不再需要在每次向复制状态添加新字段时重新编译 interfaces 包及其众多依赖项。
运行时多态性是首选。
我们设计的考量之一是如何连接软件组件。我们应该像Arc
pub struct Consensus {
artifact_pool: Arc,
state_manager: Arc ,
} 上段代码是使用运行时多态性组合组件。
pub struct Consensus {
artifact_pool: AP,
state_manager: SM,
} 上段代码使用编译时多态性组合组件。
编译时多态性是必不可少的工具,更是重量级的工具。运行时多态性需要更少的代码,且有助于更少的二进制膨胀。大多数团队成员也发现该 dyn 版本(即上述第一段代码)更易于阅读。
首选显式依赖项。
新开发人员在开发频道上最常问的问题之一是“为什么我们要显式传递loggers?全局的loggers似乎也能工作得很好”。这是个好问题。如果回到2019年我也会问同样的问题!
全局变量很糟糕,但我以前的经验表明,日志对象loggers和指标接收器(metric sinks)很特殊。哦,好吧,其实也没有那么特殊。
隐式状态依赖的常见问题在 Rust 中尤为突出。
大多数 Rust 库不依赖于真正的全局变量。传递隐式状态的常用方法是使用线程局部变量,当您生成新线程时,这可能会成为问题。新线程倾向于继承并保留线程局部变量的意外值。
默认情况下,Cargo 在测试二进制文件中并行运行测试。如果不小心通过调用堆栈对loggers进行线程处理,测试输出可能会变得无形的混乱。当后台线程需要访问日志时,通常会出现此问题。而通过显式传递loggers的方式则可以消除该问题。
在多线程环境中,对依赖于隐式状态代码的测试很困难甚至不可能。记录指标的代码就是代码。它也值得测试。
如果使用依赖于隐式状态的库,则在依赖于不同包中不兼容的库版本时,可能会引入细微的BUG。
对于这个观点,迫切需要一个例子。这里有一个小合适的故事作为映证:
我们使用普罗米修斯软件包进行指标记录。此包可以将指标注册表保留在全局变量中。
突然有一天,我们遇到了一个错误:我们无法看到某些组件的指标。我们的代码看起来是正确的,但指标却缺失了。
其中一个软件包依赖于普罗米修斯版本 0.9 ,而所有其他软件包都使用 0.10 。根据semver的说法,这些版本是不兼容的,因此cargo将两个版本链接到二进制文件中,引入了两个隐式注册表。我们仅通过 HTTP 接口公开 0.10 版本注册表。正如您正确猜测的那样,缺少的组件将指标记录到注册表中 0.9 。
而传递loggers、指标注册表和异步运行时的方式会显式地将运行时 bug 转换为编译时错误。切换到显式传递指标注册表帮助我找到并修复了该错误。
古老的 slog 包的官方文档还建议明确传递loggers:
原因是:手动传递 Logger 提供了最大的灵活性。使用slog_scope 将日志记录数据结构绑定到堆栈跟踪,这与软件的逻辑结构不同。特别是库应该向用户展示充分的灵活性,而不是使用隐式日志记录行为。
通常 Logger 实例非常适合表示的代码中的资源的数据结构,因此在构造函数中传递它们并在任何地方使用,并不难,像这样:
info!(self.log,