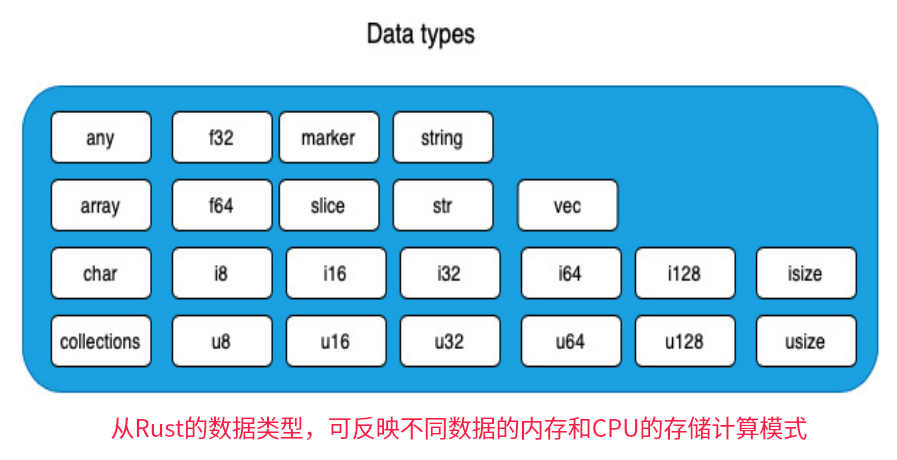
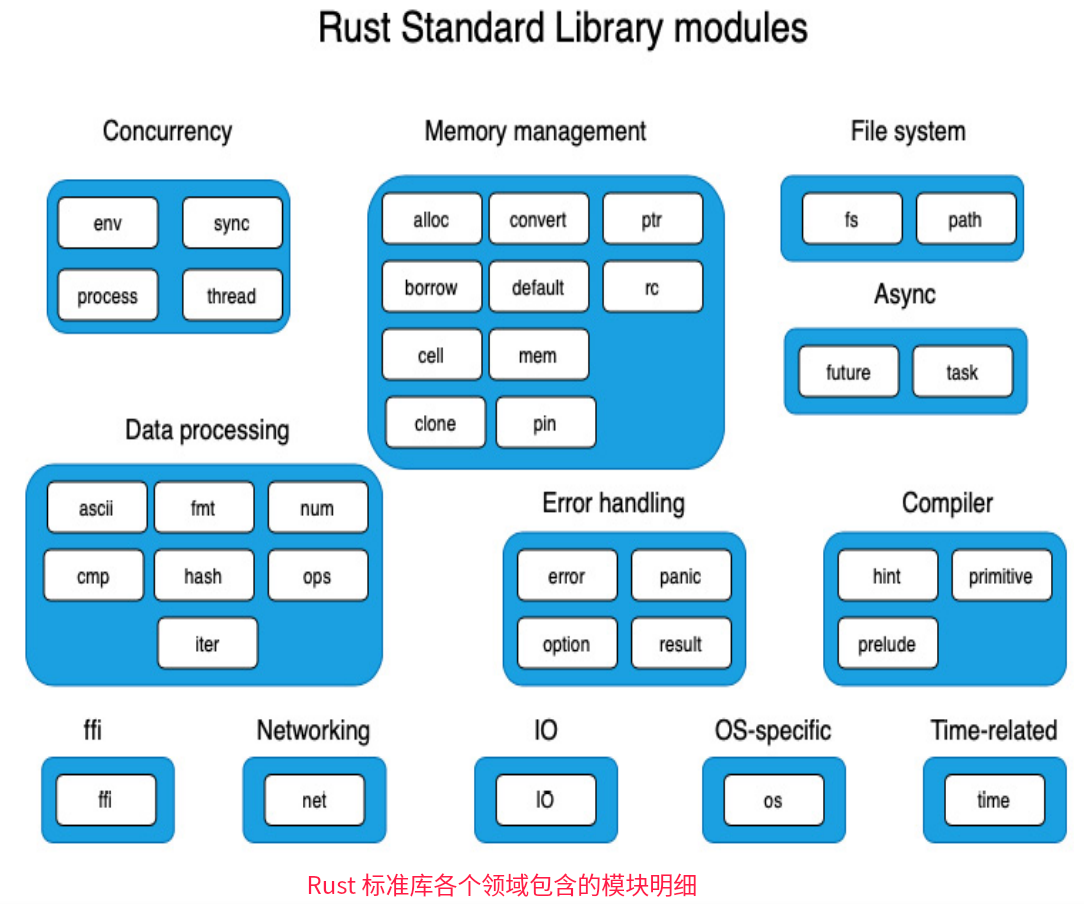
问题表现形式
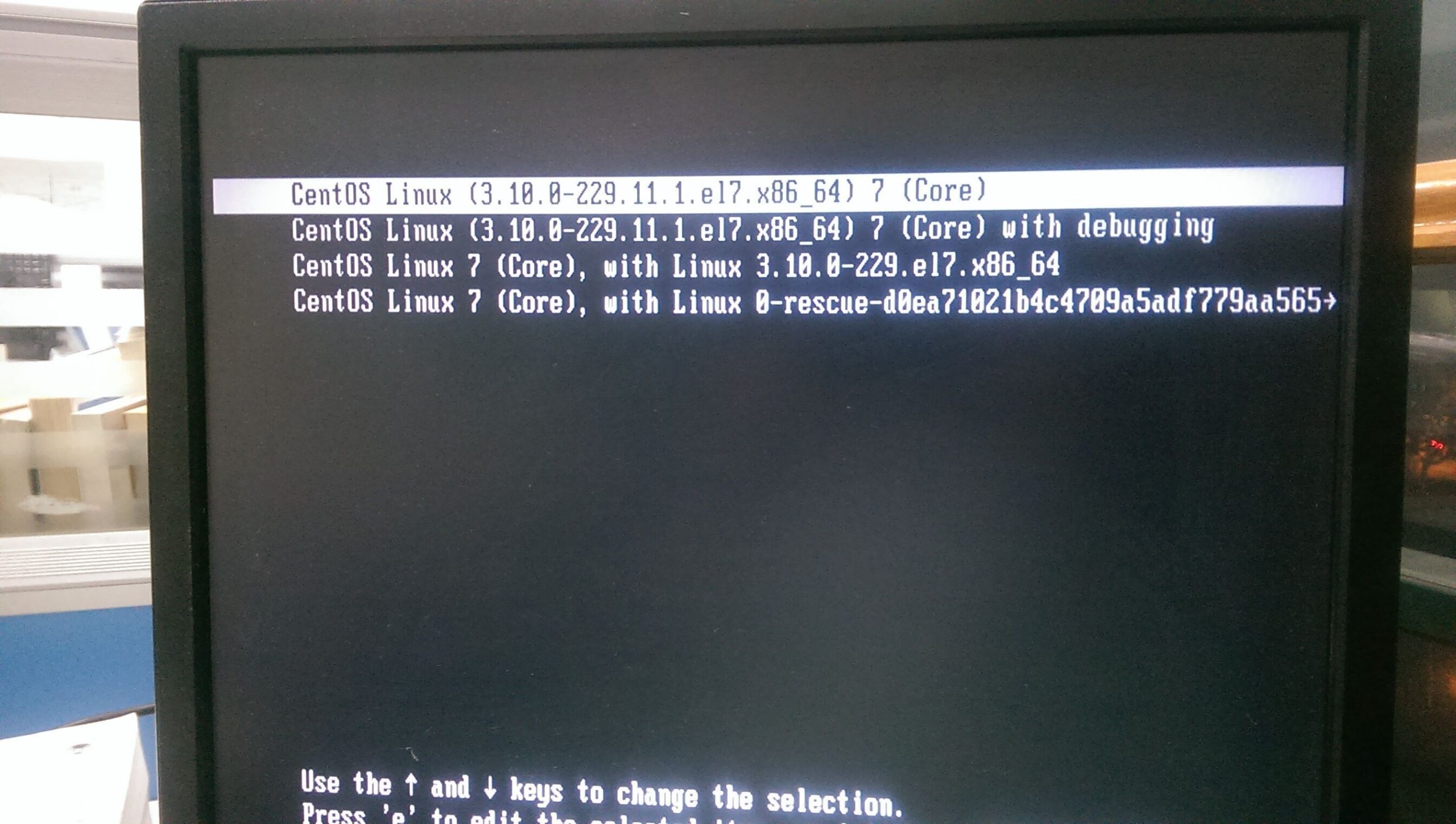
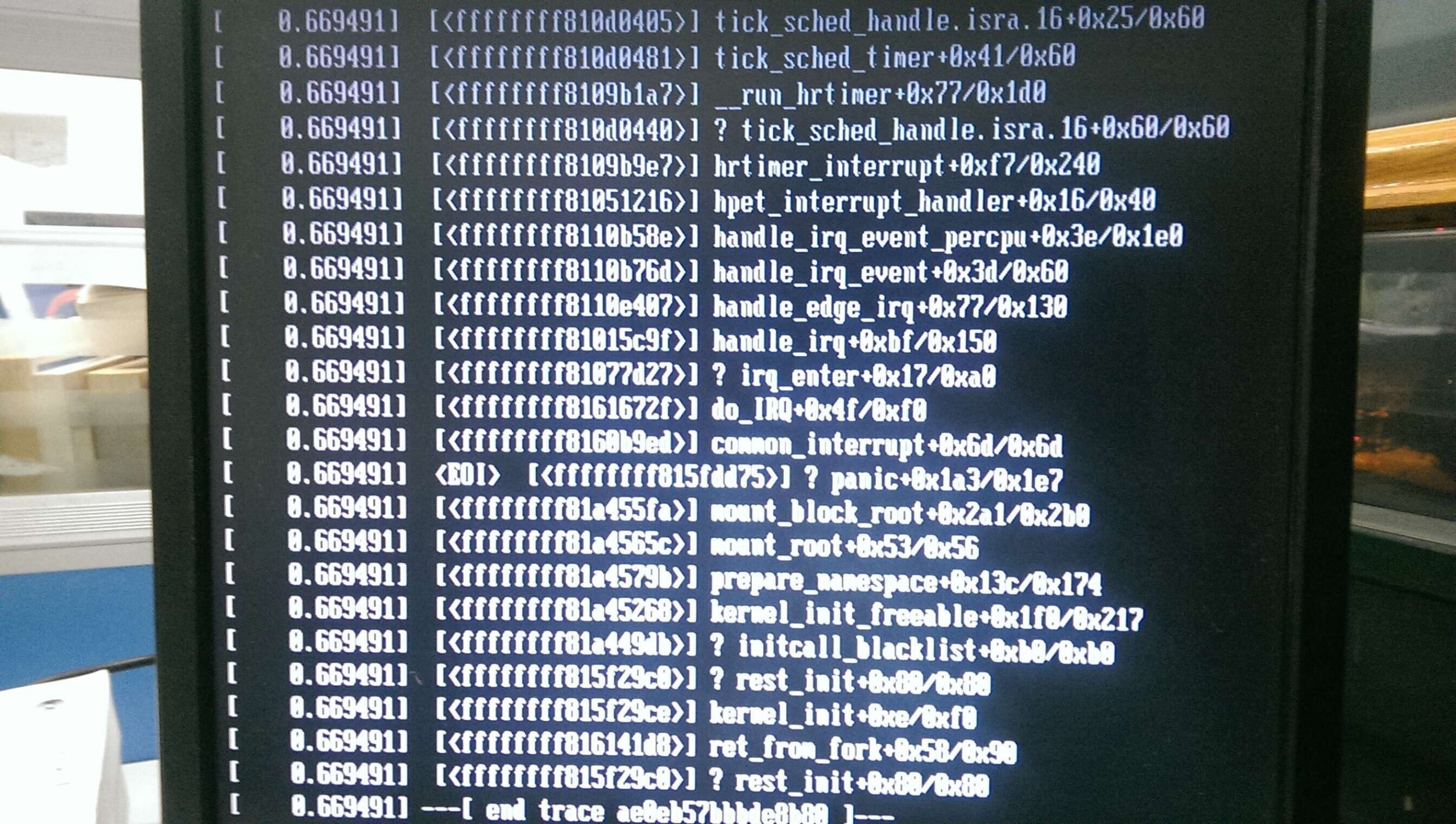
Centos9/rockylinux9 系统使用再生龙(clonezilla)硬盘对拷后,得到的新硬盘的系统启动报错信息:
timed out waiting for device /dev/mapper/rl-homeLVM的逻辑分区有 rl-root,rl-home,rl-swap
其中只有提示 rl-home的问题。但rl-home和rl-root的分区格式都是xfs(换成ext4也一样的报错)。
报错截图:
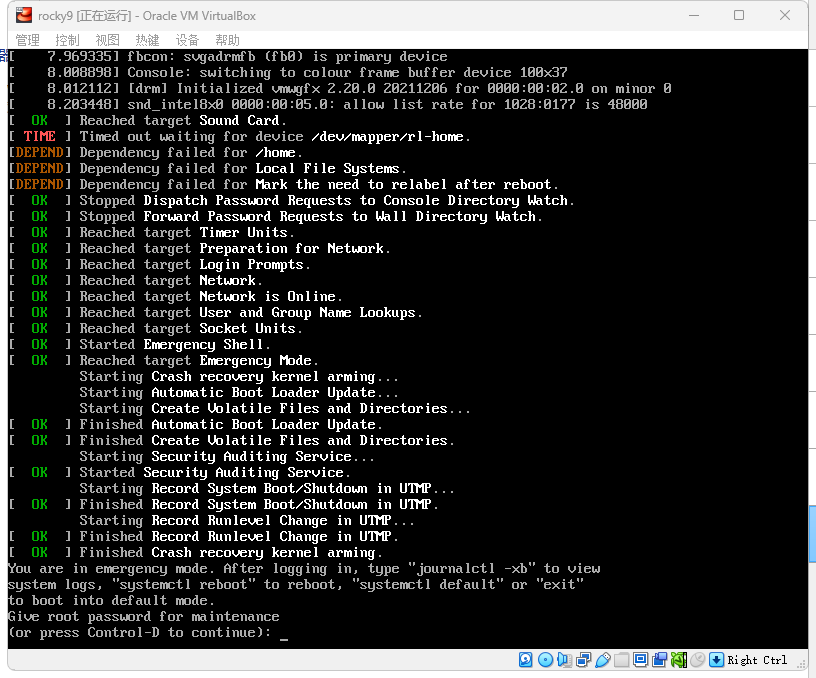
问题根源:
在 RHEL 9.0 上,LVM 使用持久命名文件 /etc/lvm/devices/system.devices 来查找 PV,例如 IDTYPE、IDNAME、DEVNAME、PVID 等(此配置在 RHEL 9.0 上默认启用,在 RHEL 8.x 上默认禁用。在 AHV 上,克隆或创建快照功能会为 SCSI 磁盘生成新的 PV(在 ESXi 和 Hyper-V 上不会发生这种情况),但持久命名文件 /etc/lvm/devices/system.devices 不会在新虚拟机启动时自动更新。在此问题中,持久命名文件 /etc/lvm/devices/system.devices 中未列出新 PV,这会导致 LVM 忽略新 PV。在操作系统启动期间,原始 PV 中所需的磁盘分区不会挂载,而是 VM 进入紧急模式。
紧急解决方式:
若要从紧急模式恢复 VM,只需执行以下步骤:
- 删除原始设备文件:
root@VM#rm /etc/lvm/devices/system.devices - 创建新的设备文件:
root@VM#vgimportdevices -a
彻底解决方式:
解决方式一:
编辑系统目录下的lvm的配置文件(/etc/lvm/lvm.conf 的 129行左右)

将其中的
#use_devicesfile=1修改为
use_devicesfile=0然后重启。问题解决。
解决方式一的一个可选后续操作为:
root@VM# rm /etc/lvm/devices/system.devices解决方式二:
要防止虚拟机进入下一个克隆/快照的紧急模式,请执行以下操作:
- 在原始 VM 上,暂时禁用设备文件:
root@VM#mv /etc/lvm/devices/system.devices /tmp/ - 创建虚拟机克隆/快照。
- 在原始 VM 上,使用设备文件恢复:
root@VM#mv /tmp/system.devices /etc/lvm/devices/ - 在复制的 VM 上,创建新的设备文件:
root@VM#vgimportdevices -a
参考资料:
… 查看余下内容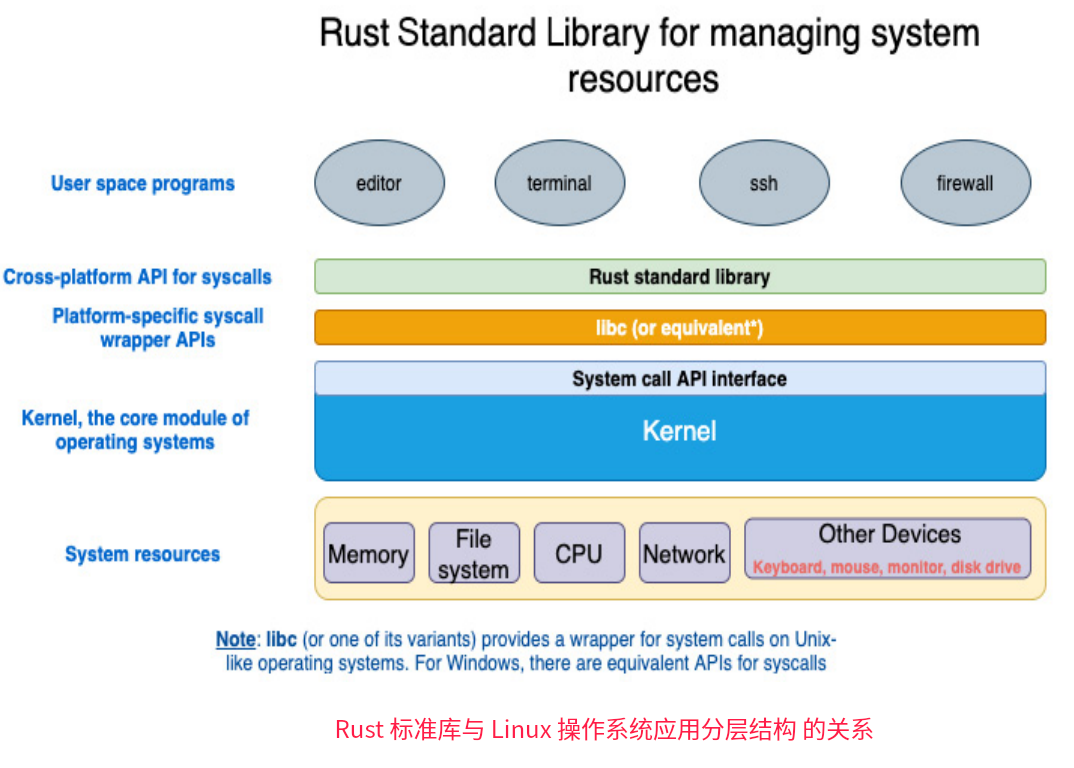
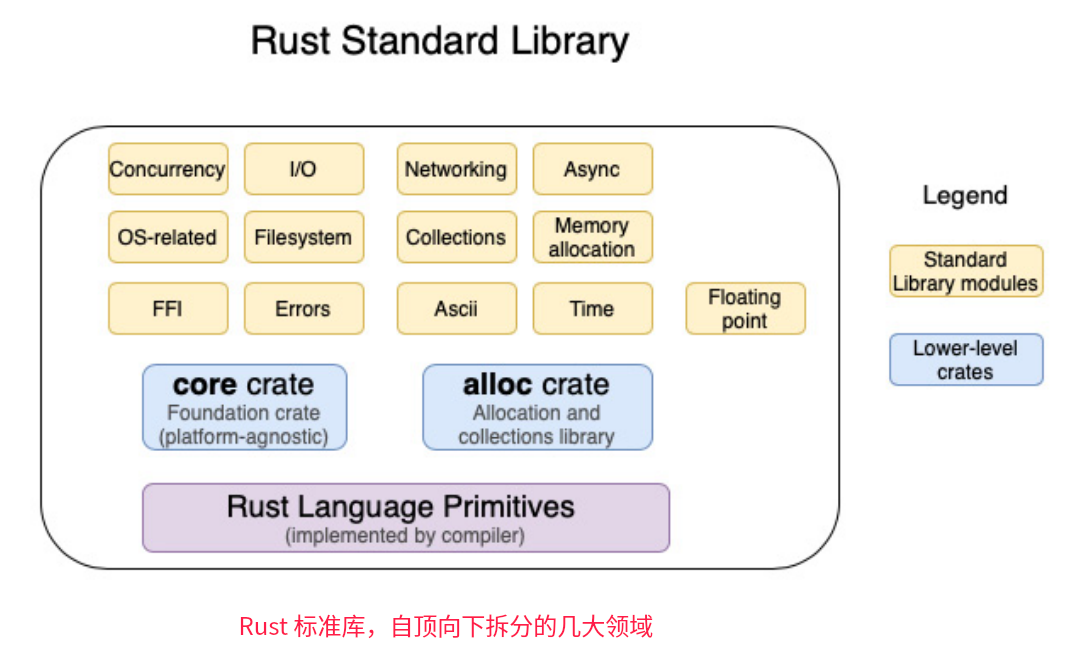 libc(或其变体)为类UNIX操作系统上的系统调用提供了一个包装器,如Linux内核实现了POSIX标准指定的数百个POSIX API(对于Windows,系统调用有等效的API,也实现了
libc(或其变体)为类UNIX操作系统上的系统调用提供了一个包装器,如Linux内核实现了POSIX标准指定的数百个POSIX API(对于Windows,系统调用有等效的API,也实现了