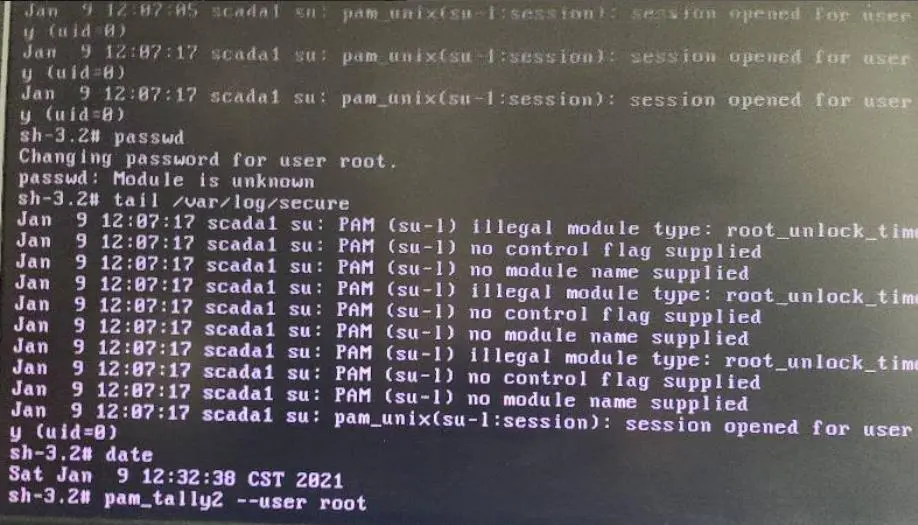
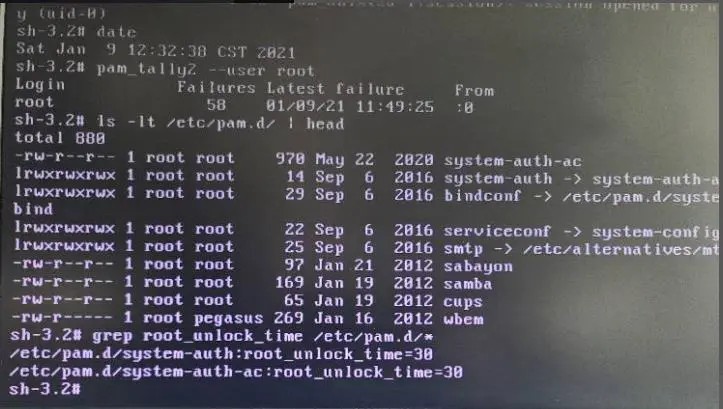
Centos 采用的防火墙firewalld简介:
firewalld 是 CentOS 和其他一些 Linux 发行版中默认使用的防火墙软件,它提供了一种灵活的方式来管理系统的网络安全和连接。
firewalld 使用 D-Bus 接口来管理网络连接,它使用基于区域的策略来控制入站和出站流量,并且可以在运行时动态更新规则。这使得 firewalld 比传统的 iptables 防火墙更加灵活和易于管理。
以下是 firewalld 的一些主要特点:
-
支持基于区域的策略:
firewalld使用基于区域的策略来控制入站和出站流量。每个区域都有一个预定义的安全级别和一组服务,这些服务定义了允许访问的端口和协议。你可以轻松地将系统接口分配给不同的区域,并在区域之间移动。 -
支持动态更新规则:
firewalld可以在运行时动态更新规则,无需重启防火墙服务。这使得添加或删除规则变得更加方便和快捷。 -
支持网络连接跟踪:
firewalld可以跟踪网络连接并在其生命周期内应用相应的规则。这使得firewalld能够更好地保护系统安全和隐私。 -
支持 IPv6:
firewalld支持 IPv6,可以轻松地管理 IPv6 网络安全。 -
支持命令行和图形界面:
firewalld提供了命令行和图形界面两种管理方式。你可以使用命令行工具firewall-cmd来管理防火墙,也可以使用图形界面工具firewall-config来配置防火墙规则。
总之,firewalld 是一个功能强大且易于管理的防火墙软件,它提供了一种灵活的方式来保护系统网络安全和连接。如果你使用 CentOS 或其他一些 Linux 发行版,firewalld 是一个值得考虑的防火墙解决方案。
firewall-cmd 的不同场景应用举例:
如果通过命令方式修改firewalld防火墙规则,则通过firewall-cmd 命令具体执行,以下是一些实际例子:
firewall-cmd 设置linux防火墙允许80端口对外访问:
firewall-cmd --zone=public --add-port=80/tcp --permanent查看当前规则:
firewall-cmd --list-all public允许特定服务通过防火墙:
firewall-cmd --zone=public --add-service=httpd --permanent让firewall-cmd命令设置的规则马上生效:
firewall-cmd --reload对于非默认端口的开放,除了要防火墙允许,还要selinux允许,
在centos7等最新的发行版上,默认启用了selinux,而selinux允许指定端口的命令是:
semanage port -a -t http_port_t -p tcp 81
semanage port -a -t ssh_port_t -p tcp 222
semanage port -a -t vnc_port_t -p tcp 5999除非关闭了selinux(命令 setenforce 0 可关闭 selinux ,如果永久关闭,可编辑/etc/sysconfig/selinux 文件将 SELINUX=enforcing 改成 SELINUX=disabled),才不需要额外执行以上命令。
要指定允许的来源ip和目标端口:
firewall-cmd --permanent --zone=public --add-rich-rule='
rule family="ipv4"
source address="10.10.99.10/32"
port protocol="tcp" port="80" accept'firewalld 根据nginx访问日志的 503 记录,自动屏蔽特定ip:
iptables 方式:
*/1 * * * * for itm in /usr/bin/tail -2000 /www/wwwlogs/site.com.log