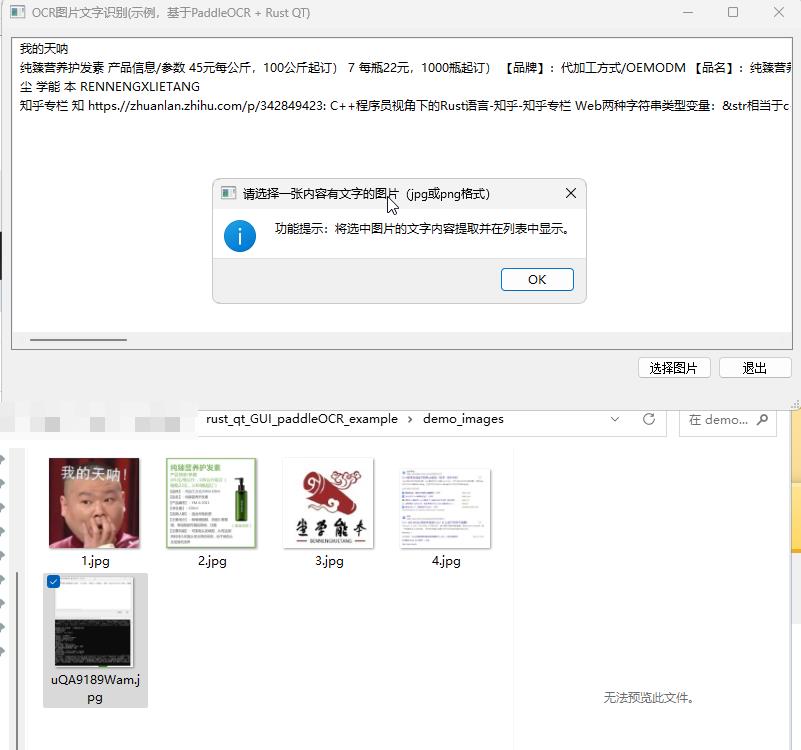
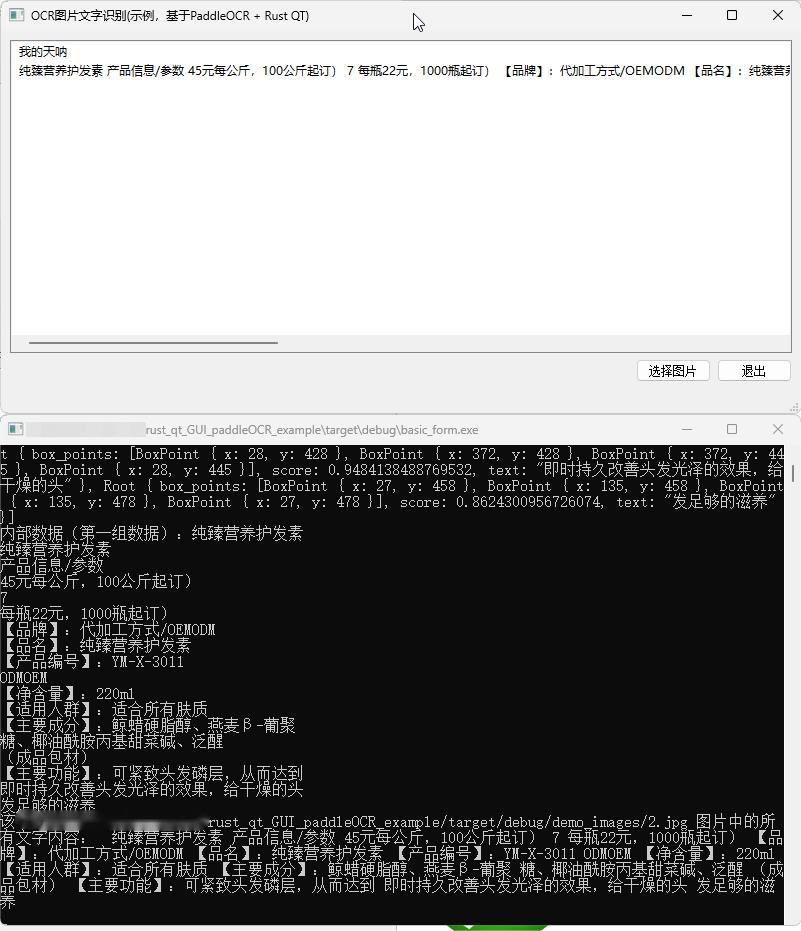
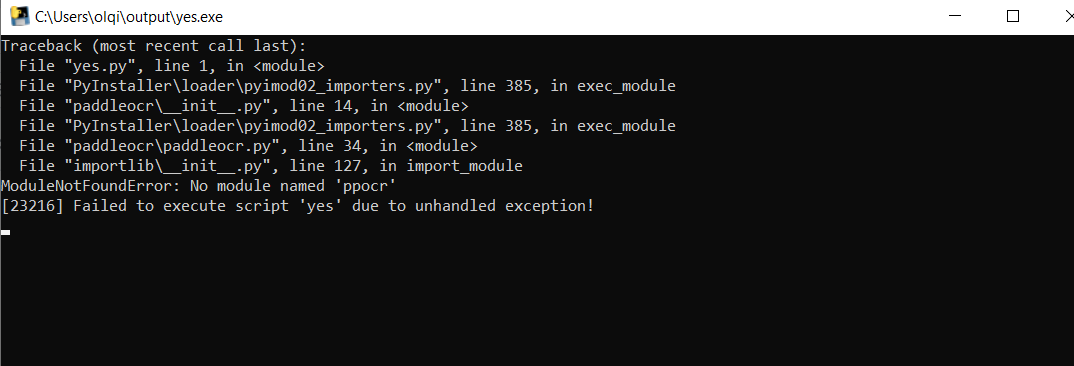
关键报错信息:
libcufft.so.11: cannot open shared object file: No such file or directory或类似的动态库缺失的报错。
完整报错信息:
Traceback (most recent call last):
File "/root/miniconda3/envs/mypy38/lib/python3.8/site-packages/torch-2.1.1-py3.8-linux-x86_64.egg/torch/__init__.py", line 174, in _load_global_deps
ctypes.CDLL(lib_path, mode=ctypes.RTLD_GLOBAL)
File "/root/miniconda3/envs/mypy38/lib/python3.8/ctypes/__init__.py", line 373, in __init__
self._handle = _dlopen(self._name, mode)
OSError: libcufft.so.11: cannot open shared object file: No such file or directory
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "main.py", line 1, in
from simcse import SimCSE
File "/root/SimCSE/simcse/__init__.py", line 1, in
from .tool import SimCSE
File "/root/SimCSE/simcse/tool.py", line 5, in
import torch
File "/root/miniconda3/envs/mypy38/lib/python3.8/site-packages/torch-2.1.1-py3.8-linux-x86_64.egg/torch/__init__.py", line 234, in
_load_global_deps()
File "/root/miniconda3/envs/mypy38/lib/python3.8/site-packages/torch-2.1.1-py3.8-linux-x86_64.egg/torch/__init__.py", line 195, in _load_global_deps
_preload_cuda_deps(lib_folder, lib_name)
File "/root/miniconda3/envs/mypy38/lib/python3.8/site-packages/torch-2.1.1-py3.8-linux-x86_64.egg/torch/__init__.py",