Linux的层级架构
每个操作系统都有一个内核,内核封装了底层硬件设备管理、内存管理、网络数据协议转化和收发传输、文件系统读写等。从这个图可以看到,内核将系统硬件与应用程序进程连接起来,隐藏了上层下层交互的一些细节,各司其职。
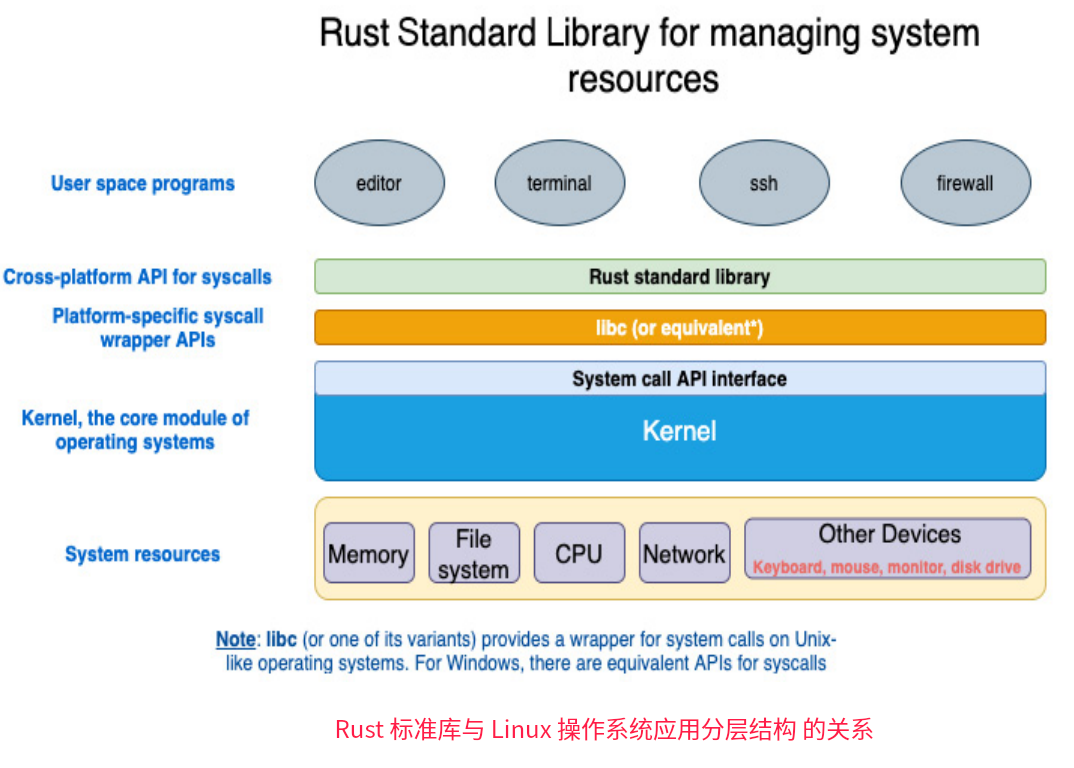
这些分层包括:
- 用户空间程序
- 编译器
- 终端
- 防火墙
- 系统调用的跨平台API(特定于平台的系统调用包装API)
- Rust标准库
- libc(或等效的API)
- kernel,操作系统的核心模块
- 系统资源
- 内存
- 文件系统
- 网络
- 硬件和其他设备(包括键盘、鼠标、监视器、磁盘驱动器)
Rust的标准库的功能划分
而Rust标准库,很好的利用了操作系统内核提供的API。
Rust标准库是Rust程序进入Linux操作系统内核函数的主要接口,它在内部使用libc(在Windows系统使用其他等效的库)来调用内核提供的系统调用。
从Rust程序中发起系统调用,以实现管理和操作各种系统资源(如图)。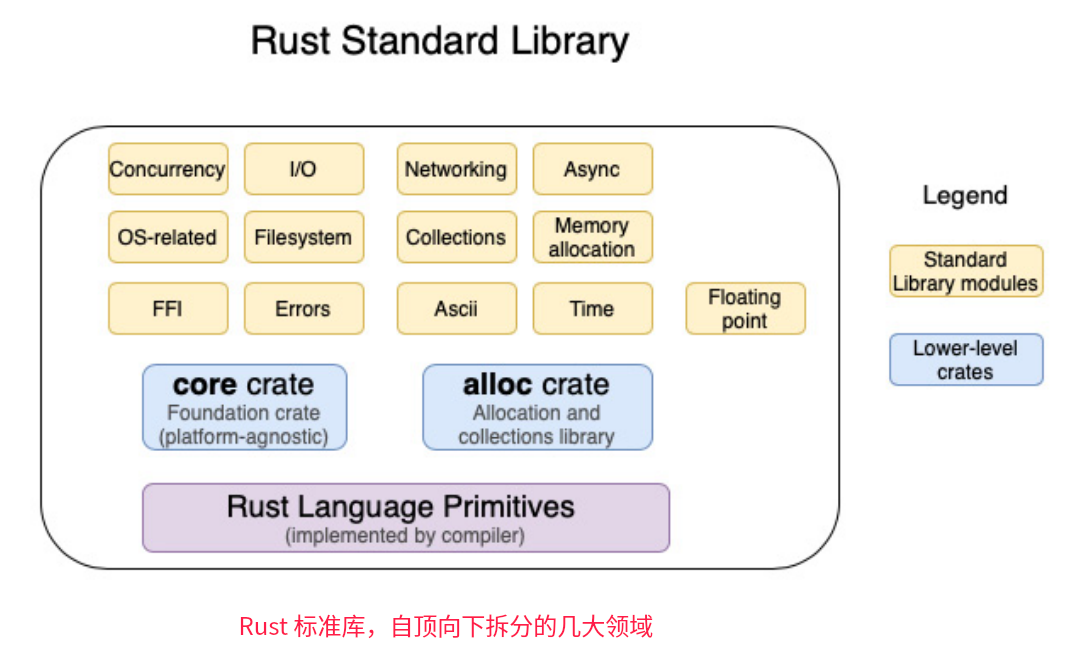 libc(或其变体)为类UNIX操作系统上的系统调用提供了一个包装器,如Linux内核实现了POSIX标准指定的数百个POSIX API(对于Windows,系统调用有等效的API,也实现了POSIX标准)。
libc(或其变体)为类UNIX操作系统上的系统调用提供了一个包装器,如Linux内核实现了POSIX标准指定的数百个POSIX API(对于Windows,系统调用有等效的API,也实现了POSIX标准)。
作为标准库,Rust标准库是跨平台的,Rust标准库的系统调用的细节是从Rust开发人员那里抽象出来的。Rust也支持不依赖于标准库的运行方式(no_std 方式),Rust直接操控底层硬件(如应用在嵌入式系统开发场景),此时Rust就做了操作系统本身的工作。
对于大部分软件开发工程师而言,他们用Rust主要开发应用层软件,也就是运行在用户空间的程序。它们基于标准库编写,实现各种业务功能。应用层的软件并非所有模块和函数都涉及到系统调用(例如一些用于操作字符串和处理错误的函数,就无需调用系统调用)。
Rust标准库包括几大领域的模块,包括四大类:
第一类,Rust语言原语
即Rust Language Primitives:Rust 语言的基本元素或基本类型(如下图)。
如有符号整数、布尔值、浮点数、字符、字符串、数组、元组、切片。这些由Rust编译器负责实现。
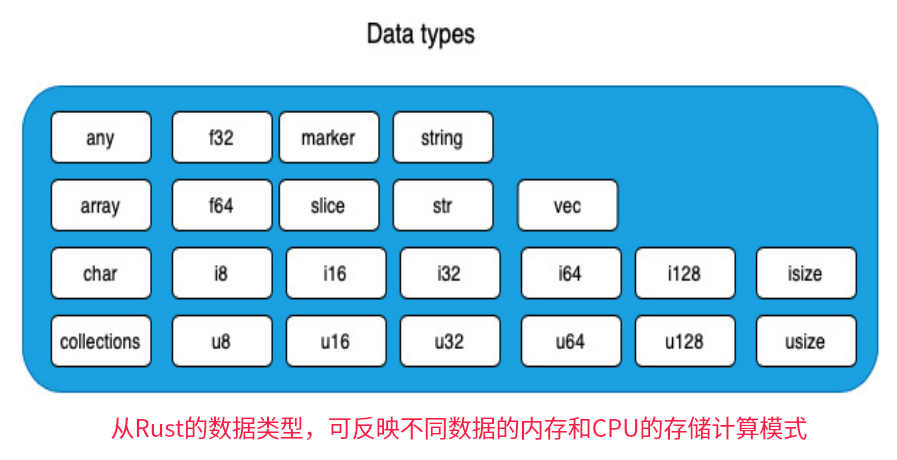
Rust标准包括原语,并在它们之上构建。
第二类,alloc crate
与堆分配值的内存分配相关的类型、函数和特征。
包括集合(Vec、String等集合)、智能指针类型(Box<T>)、引用计数指针(Rc<T>)和原子引用计数指针(Arc<T>))。
第三类,core crate
作为Rust标准库的基础。充当Rust语言与标准库之间的链接,提供在Rust原语之上实现的类型、特征、常量和函数,并为所有Rust代码提供基础构建块,它是跨平台的,没有任何指向操作系统或其他外部依赖的链接。由于较少直接用到core crate,所以本文不做过多介绍。
第四类,模块(标准库的其他crate)
是标准库的一部分,模块crate包括针对并发、I/O,文件系统、网络、异步I/O、错误处理等功能,以及与特定操作系统相关的函数,Rust的官网对std有专门的文档。例如
- 为用户程序在多个线程上并发运行的功能在std::thread模块中;
- 用于处理同步I/O的功能在std::io模块中提供;
- 针对特定os的模块,主要在std::os模块中实现。
下图展示了Rust标准库各个领域功能涉及到的具体std模块(如std::io、std::os等)
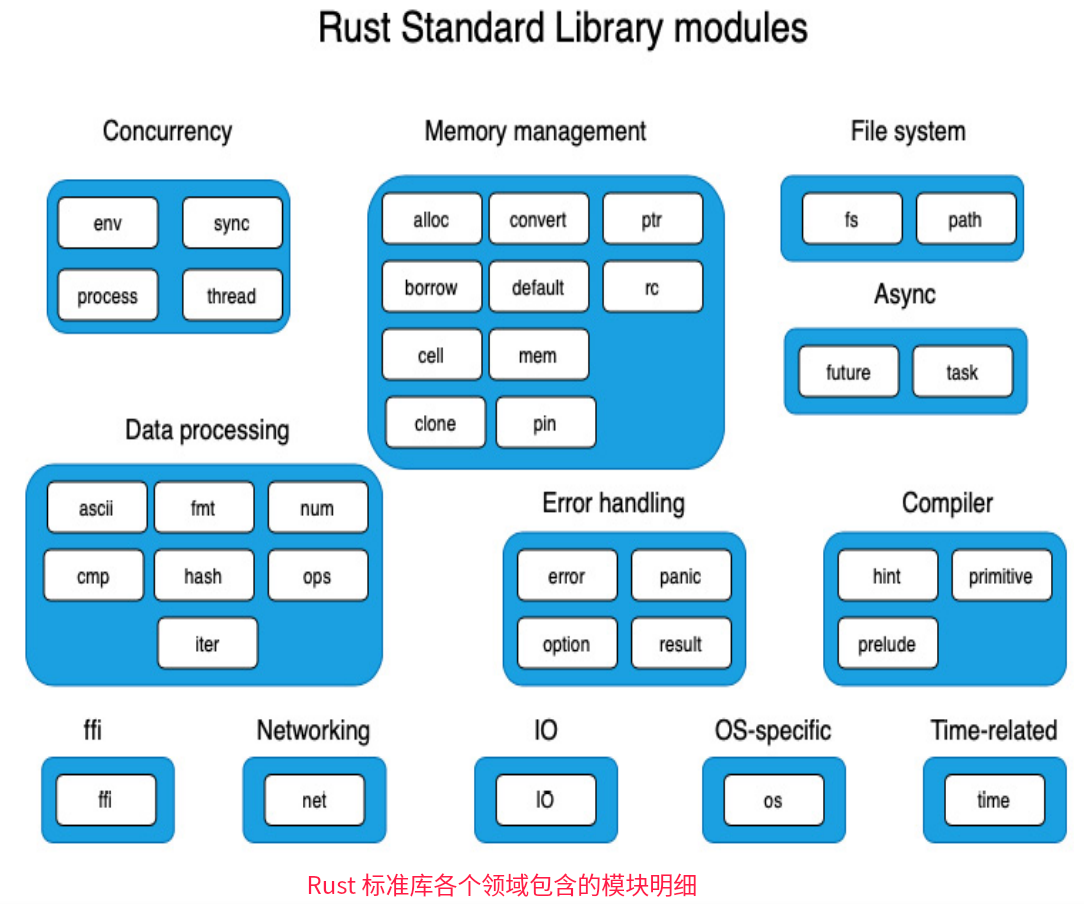
以下着重对第四类的主要 crate 做一介绍,并附上文档地址
Rust的并发控制相关模块 conurrency:
Rust的内存管理相关模块 memory management:
Rust的文件系统操作相关模块 File system:
Rust的数据处理相关模块 data processing:
Rust的错误处理相关模块 Error handling:
Rust的编译处理相关模块 compiler:
Rust的跨语言调用相关模块: FFI
| 模块名 |
说明 |
| std::ffi 模块 |
提供了与外部函数接口(Foreign Function Interface,FFI)相关的功能,用于与其他语言或库进行交互。 |
Rust的网络处理功能模块 Networking:
| 模块名 |
说明 |
| std::net 模块 |
提供了与网络编程相关的功能,包括网络协议、套接字(Socket)和网络地址等。 |
Rust的IO处理模块:
Rust的OS特定的功能模块:
| 模块名 |
说明 |
| std::os 模块 |
提供了与操作系统相关的功能,包括文件系统操作、进程管理和系统信息等。 |
Rust的时间处理模块:
…
查看余下内容